Mỗi Tuần Một Database #2: Apache HBase - "Gã khổng lồ" từng gánh vác hàng tỷ tin nhắn của Facebook
Nếu bạn quay ngược thời gian về năm 2010, Facebook đang đối mặt với một bài toán kỹ thuật "đau đầu". Họ muốn hợp nhất Chat, SMS và Email vào một hộp thư duy nhất (Facebook Messages). Hệ thống MySQL sharding cũ kỹ của họ bắt đầu "hụt hơi" trước lượng dữ liệu khổng lồ tăng lên từng giây. Họ cần một thứ gì đó có khả năng ghi cực nhanh (write-heavy), mở rộng không giới hạn và không bao giờ được phép sập.
Câu trả lời của họ lúc đó chính là Apache HBase.
Dù sau này Facebook đã chuyển sang MyRocks để tối ưu hóa cho phần cứng flash, nhưng giai đoạn sử dụng HBase chính là minh chứng hùng hồn nhất cho sức mạnh của công nghệ này. Vậy HBase là gì mà có thể "gánh team" dữ liệu lớn tốt đến vậy?
1. Apache HBase là gì?
HBase là một cơ sở dữ liệu phân tán, mã nguồn mở, thuộc loại NoSQL và hướng cột (column-oriented). Nó được mô phỏng theo Google Bigtable và chạy trên nền tảng Apache Hadoop (HDFS).
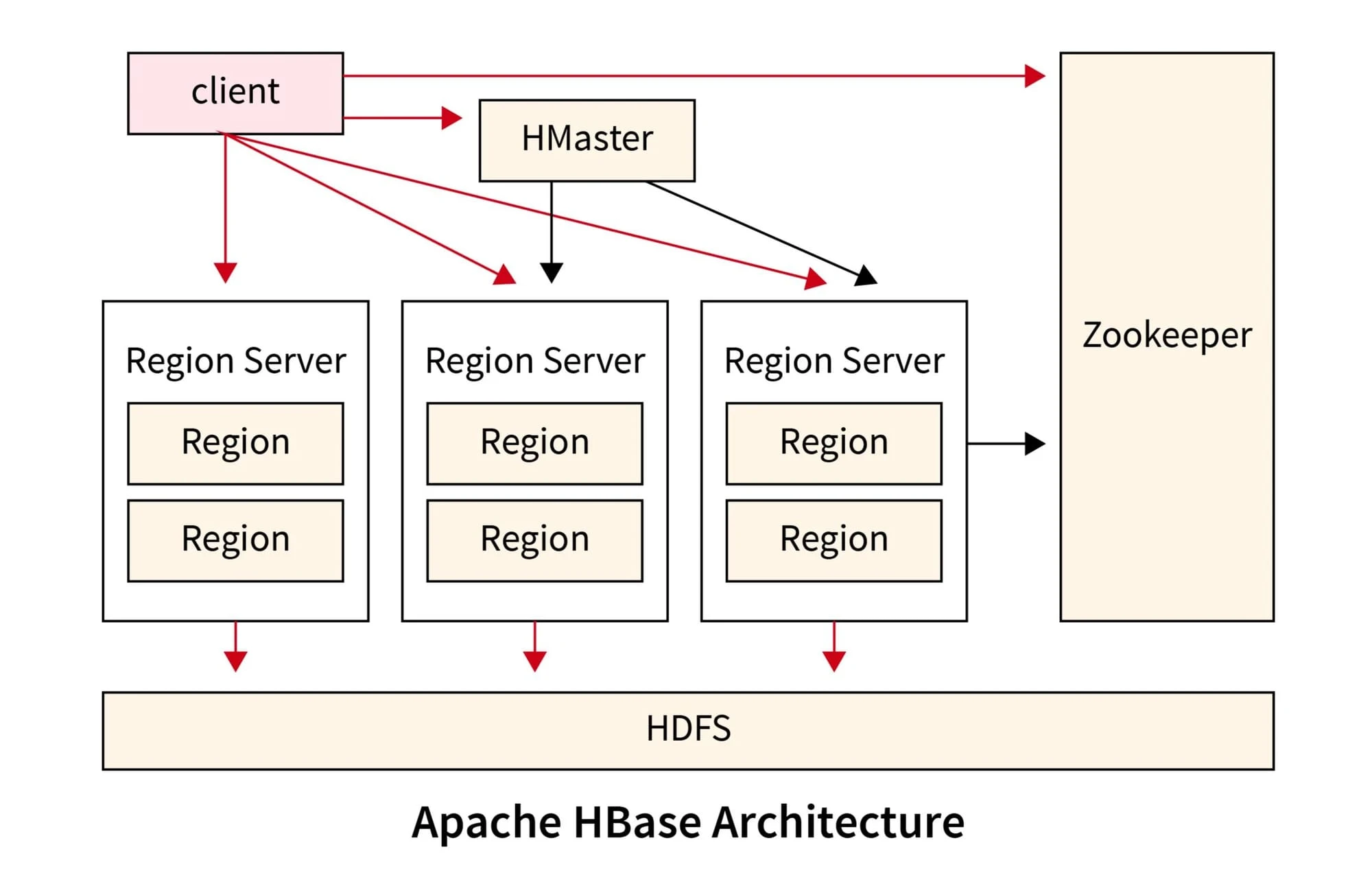
Nếu HDFS là "kho chứa hàng" khổng lồ (file system), thì HBase chính là "người thủ kho" thông minh giúp bạn tìm và ghi chép từng món hàng cụ thể trong kho đó với tốc độ cực nhanh.
2. HBase lưu trữ dữ liệu như thế nào? (Kiến trúc & Data Model)
Khác với RDBMS truyền thống (như MySQL, PostgreSQL) lưu dữ liệu theo dạng bảng với các dòng và cột cố định, HBase nhìn dữ liệu như một bản đồ đa chiều (Multi-dimensional sorted map).
Các thành phần chính:

- Row Key (Khóa dòng): Đây là thứ quan trọng nhất. Mọi dữ liệu đều được sắp xếp theo thứ tự từ điển (lexicographical) của Row Key. Việc thiết kế Row Key quyết định 90% hiệu năng của hệ thống.
- Column Family (Họ cột): Các cột trong HBase được gom nhóm vào các "Họ". Dữ liệu trong cùng một Column Family được lưu trữ vật lý cùng nhau trên đĩa. (Ví dụ: Family Info chứa tên, tuổi; Family Log chứa lịch sử đăng nhập).
- Column Qualifier: Tên cột cụ thể trong một họ (Ví dụ: Info:Name, Info:Age). Bạn có thể thêm cột mới bất cứ lúc nào mà không cần sửa schema (cấu trúc).
- Timestamp: Mỗi ô dữ liệu (Cell) có thể lưu nhiều phiên bản khác nhau dựa trên thời gian.
- Cell: Giao điểm của Row Key + Column Family + Column Qualifier + Timestamp. Dữ liệu trong Cell chỉ là một chuỗi byte (byte array), HBase không quan tâm đó là chuỗi, số hay ảnh.
Cơ chế lưu trữ vật lý:
HBase là một hệ thống Sparse (Thưa thớt). Nếu một ô không có dữ liệu, nó sẽ không chiếm bất kỳ dung lượng nào. Điều này khác hẳn với RDBMS nơi giá trị NULL vẫn cần xử lý.
3. Ưu điểm và Nhược điểm
✅ Ưu điểm (Tại sao chọn HBase?)
- Scalability (Khả năng mở rộng): Mở rộng tuyến tính. Cần lưu thêm 100TB? Chỉ cần gắn thêm máy chủ (Node) vào cụm, không cần tắt hệ thống.
- High Write Throughput: Nhờ kiến trúc LSM Tree (Log-Structured Merge-tree), HBase ghi dữ liệu vào bộ nhớ (MemStore) trước khi đẩy xuống đĩa, giúp tốc độ ghi cực nhanh.
- Strong Consistency: Khác với các hệ NoSQL "Eventual Consistency" (như Cassandra), HBase đảm bảo tính nhất quán mạnh. Khi bạn ghi thành công, người đọc sau đó chắc chắn sẽ thấy dữ liệu mới nhất.
- Flexible Schema: Bạn không cần định nghĩa trước tất cả các cột.
❌ Nhược điểm (Cần cân nhắc)
- Không hỗ trợ SQL chuẩn: Bạn không thể dùng SELECT * FROM table JOIN table.... HBase không hỗ trợ JOIN phức tạp. Mọi thứ phải được thiết kế (denormalize) từ đầu.
- Độ trễ (Latency): HBase nhanh, nhưng không nhanh bằng các hệ thống thuần in-memory (như Redis).
- Phức tạp: Vận hành một cụm HBase cần kiến thức về Hadoop, Zookeeper và HDFS. Rất dễ gặp lỗi nếu không cấu hình đúng (ví dụ: vấn đề Garbage Collection trong Java).
4. Các Use-case phổ biến của HBase
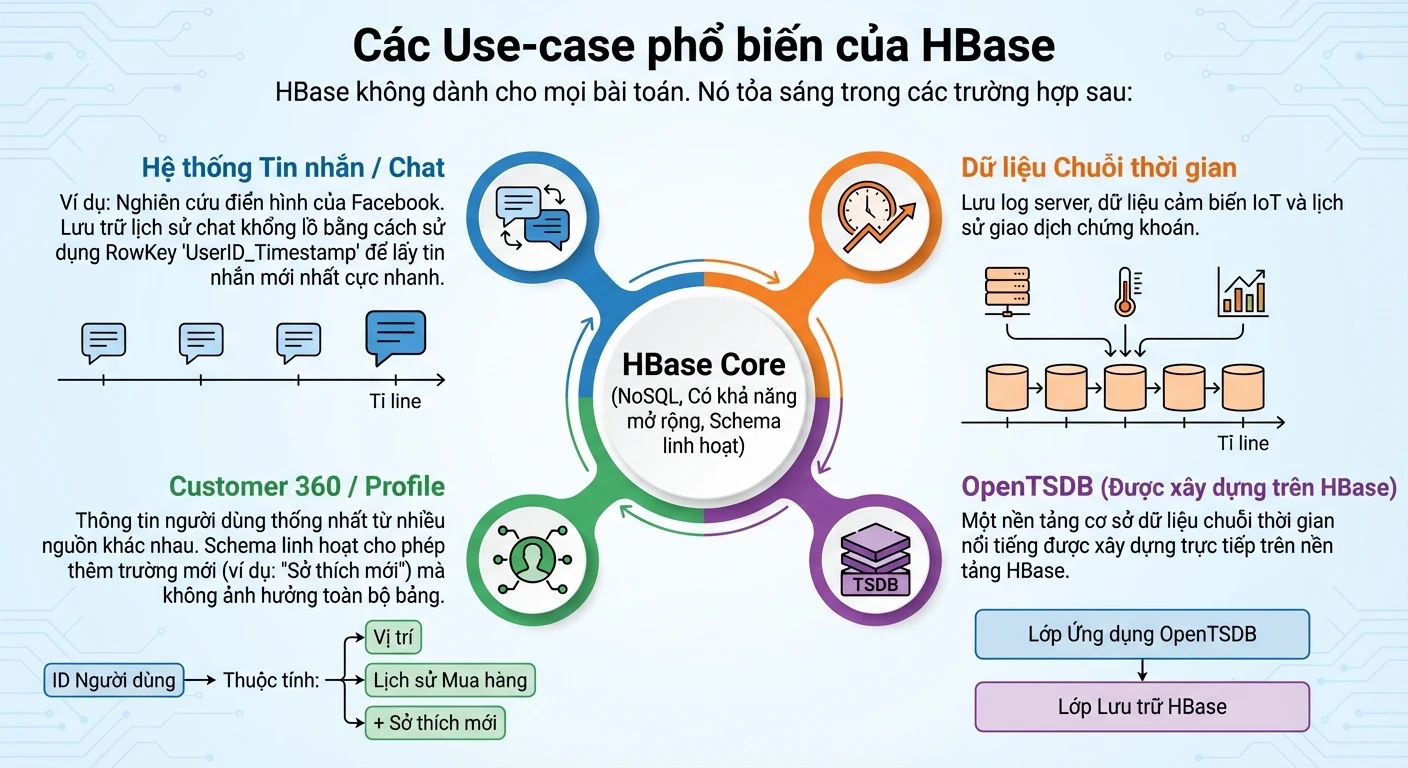
HBase không dành cho mọi bài toán. Nó tỏa sáng trong các trường hợp sau:
- Hệ thống tin nhắn/Chat (Messaging): Như case study của Facebook. Lưu trữ lịch sử chat khổng lồ với RowKey là UserID_Timestamp để lấy tin nhắn mới nhất cực nhanh.
- Dữ liệu chuỗi thời gian (Time-series Data): Lưu log server, dữ liệu cảm biến IoT, lịch sử giao dịch chứng khoán.
- Customer 360 / Profile: Lưu trữ thông tin người dùng từ nhiều nguồn khác nhau. Vì schema linh hoạt, bạn có thể thêm trường dữ liệu mới (ví dụ: "Sở thích mới") mà không ảnh hưởng toàn bộ bảng.
- OpenTSDB: Một cơ sở dữ liệu time-series nổi tiếng được xây dựng ngay trên nền tảng HBase.
5. Minh họa Query trong HBase (Sử dụng HBase Shell)
Trong HBase, chúng ta không dùng SQL (trừ khi dùng thêm công cụ như Apache Phoenix). Chúng ta dùng các lệnh API. Dưới đây là ví dụ minh họa bằng HBase Shell:
Kịch bản: Lưu trữ tin nhắn của người dùng.
Bước 1: Tạo bảng
Tạo bảng tên là messenger với 2 họ cột: msg (nội dung tin nhắn) và meta (thông tin phụ).
create 'messenger', 'msg', 'meta'Bước 2: Ghi dữ liệu (PUT)
Cấu trúc lệnh: put 'tên_bảng', 'row_key', 'họ:cột', 'giá_trị'
Giả sử RowKey được thiết kế là: UserID_Timestamp (để tin nhắn của 1 user nằm cạnh nhau)
# User 123 nhắn tin lúc timestamp 1001
put 'messenger', 'u123_1001', 'msg:content', 'Hello world'
put 'messenger', 'u123_1001', 'meta:sender', 'u123'
put 'messenger', 'u123_1001', 'meta:type', 'text'
# User 123 nhắn tin tiếp theo lúc timestamp 1002
put 'messenger', 'u123_1002', 'msg:content', 'HBase is cool'Bước 3: Đọc dữ liệu cụ thể (GET)
Lấy toàn bộ thông tin của dòng u123_1001.
get 'messenger', 'u123_1001'Bước 4: Quét dữ liệu (SCAN)
Đây là sức mạnh của HBase. Lấy tất cả tin nhắn của User 123. Vì RowKey được sắp xếp, việc này rất nhanh.
scan 'messenger', {STARTROW => 'u123_', ENDROW => 'u124_'}Kết luận
Apache HBase không đơn thuần là một giải pháp thay thế cho cơ sở dữ liệu quan hệ (RDBMS), mà là sự hiện thực hóa của tư duy thiết kế hệ thống phân tán (Distributed System Design) trong kỷ nguyên Big Data.
Sự dịch chuyển từ các mô hình lưu trữ truyền thống sang kiến trúc hướng cột (Column-oriented) và cơ chế LSM Tree (Log-Structured Merge-tree) của HBase phản ánh một sự đánh đổi chiến lược trong kỹ thuật: chấp nhận sự phức tạp trong vận hành và hy sinh các truy vấn quan hệ phức tạp để đạt được khả năng mở rộng tuyến tính (Linear Scalability) và tính nhất quán mạnh (Strong Consistency) ở quy mô Petabyte.
Mặc dù các tập đoàn công nghệ lớn như Meta (Facebook) đã dần chuyển dịch sang các giải pháp chuyên biệt hóa hơn (như MyRocks) để tối ưu chi phí trên phần cứng hiện đại, nhưng vị thế của HBase trong hệ sinh thái Hadoop vẫn là nền tảng tham chiếu quan trọng. Đối với các kiến trúc sư giải pháp, việc lựa chọn HBase không chỉ dừng lại ở việc lưu trữ dữ liệu, mà là xác định một chiến lược dài hạn cho các hệ thống yêu cầu thông lượng ghi cao (High Write Throughput) và độ tin cậy tuyệt đối trong môi trường phân tán.


