
Mỗi Tuần Một Database #3: Elasticsearch: Gã khổng lồ đứng sau ô tìm kiếm của GitHub
Hãy thử tưởng tượng bạn là kỹ sư tại GitHub vào những năm 2013. Bạn đang lưu trữ hàng tỷ dòng mã nguồn (source code) từ hàng triệu kho chứa (repository) khác nhau. Một người dùng gõ vào thanh tìm kiếm từ khóa function login(). Nhiệm vụ của bạn là phải tìm chính xác đoạn code đó trong vài mili-giây.
Nếu bạn dùng câu lệnh SQL LIKE %login()% trên MySQL, hệ thống sẽ sập ngay lập tức vì phải quét toàn bộ bảng (full table scan). GitHub cần một giải pháp không chỉ "lưu" dữ liệu, mà phải "hiểu" và "đánh chỉ mục" (index) văn bản để tìm kiếm tức thì.
Giải pháp họ chọn (và vẫn dùng đến nay như một phần cốt lõi) là Elasticsearch.
Trong suốt gần một thập kỷ, Elasticsearch đã đóng vai trò là "bộ não" xử lý tìm kiếm cho GitHub, gánh vác việc đánh chỉ mục từ 5 triệu kho chứa (repository) ban đầu lên tới con số khổng lồ 53 tỷ file mã nguồn vào năm 2021. Dù sau này GitHub đã chuyển sang giải pháp riêng (Blackbird) để tối ưu hóa đặc thù, nhưng giai đoạn họ sử dụng Elasticsearch vẫn luôn được xem là một "bài học giáo khoa" kinh điển về khả năng mở rộng trong giới công nghệ.
Vậy Elasticsearch là gì mà có thể làm được điều kỳ diệu đó?
1. Elasticsearch là gì?
Elasticsearch là một công cụ tìm kiếm và phân tích (search and analytics engine) phân tán, mã nguồn mở, được xây dựng dựa trên nền tảng thư viện Apache Lucene.
Khác với cơ sở dữ liệu quan hệ (RDBMS) lưu dữ liệu dạng dòng và cột, Elasticsearch lưu dữ liệu dạng văn bản JSON không cấu trúc (NoSQL). Nó được thiết kế để giải quyết bài toán: Tìm kiếm dữ liệu phi cấu trúc với tốc độ gần như thời gian thực (Near Real-time).
Nó thường được biết đến như trái tim của ELK Stack (Elasticsearch, Logstash, Kibana) - bộ công cụ giám sát hệ thống phổ biến nhất thế giới.
2. Kiến trúc & "Ma thuật" Inverted Index
Nếu sức mạnh của HBase nằm ở LSM Tree, thì sức mạnh của Elasticsearch nằm ở Inverted Index (Chỉ mục ngược).
Inverted Index hoạt động ra sao?
Hãy tưởng tượng phần "Mục lục từ khóa" ở cuối một cuốn sách giáo khoa.
- Thay vì lật từng trang để tìm chữ "DNA", bạn mở mục lục, thấy chữ "DNA" nằm ở trang 10, 15, 80.
- Elasticsearch làm hệt như vậy. Khi bạn lưu câu: "Facebook dùng HBase".
- Nó sẽ tách từ (Tokenize) và lưu lại:
- facebook -> trỏ đến Document A
- dùng -> trỏ đến Document A
- hbase -> trỏ đến Document A
Khi tìm kiếm, nó chỉ cần tra bảng chỉ mục này, không cần quét dữ liệu gốc.
Các thành phần kiến trúc:
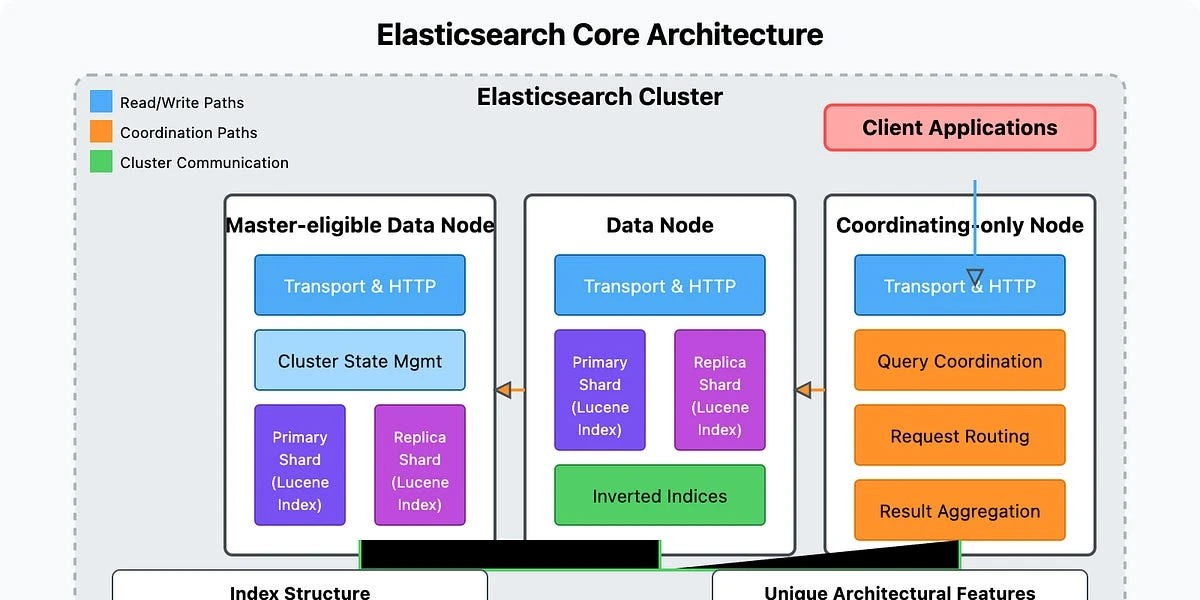
- Cluster: Một tập hợp các máy chủ (Node) liên kết với nhau.
- Node: Một máy chủ đơn lẻ lưu trữ dữ liệu.
- Index: Tương đương với "Database" hoặc "Table" trong SQL. Là tập hợp các văn bản có đặc điểm tương tự.
- Document: Tương đương với "Row" trong SQL. Là một đối tượng JSON (ví dụ: thông tin 1 sản phẩm).
- Shards (Phân mảnh): Một Index lớn có thể được chia nhỏ thành nhiều Shard để lưu trên nhiều Node khác nhau (giúp mở rộng ngang).
- Replica: Bản sao lưu của Shard để đảm bảo an toàn dữ liệu nếu một Node bị chết.
3. Ưu điểm và Nhược điểm
✅ Ưu điểm (Tại sao chọn Elasticsearch?)
- Full-text Search cực mạnh: Hỗ trợ tìm kiếm mờ (Fuzzy search - gõ sai chính tả vẫn tìm ra), tìm kiếm đồng nghĩa, tự động chấm điểm độ phù hợp (Relevance scoring - kết quả nào khớp nhất hiện lên đầu).
- Tốc độ: Truy vấn dữ liệu cực nhanh nhờ Inverted Index, ngay cả trên tập dữ liệu hàng tỷ bản ghi.
- Scalability (Mở rộng): Dễ dàng thêm Node mới vào Cluster, hệ thống tự động cân bằng lại Shard (Rebalancing).
- Phân tích (Analytics): Không chỉ tìm kiếm, ES hỗ trợ Aggregation (tương tự GROUP BY trong SQL) rất mạnh để vẽ biểu đồ, tính toán thống kê.
❌ Nhược điểm (Cần cân nhắc)
- Ngốn tài nguyên: Elasticsearch "ăn" RAM rất khủng khiếp (do Java Heap). Chi phí hạ tầng thường cao.
- Không phải là Primary Database: ES không hỗ trợ Transaction (ACID) chặt chẽ như MySQL/PostgreSQL. Không nên dùng nó làm nơi lưu trữ dữ liệu gốc duy nhất (Source of Truth). Dữ liệu thường bị mất nếu cấu hình không chuẩn khi có sự cố mạng (Split-brain).
- Cập nhật tốn kém: Trong ES, không có khái niệm "Update" thực sự. Khi bạn sửa 1 dòng, ES sẽ đánh dấu dòng cũ là "đã xóa" và tạo một dòng mới. Nếu update quá nhiều sẽ làm giảm hiệu năng.
4. Các Use-case phổ biến
- Chức năng tìm kiếm trong Ứng dụng/E-commerce: Tiki, Shopee hay Netflix dùng ES để khi bạn gõ "iPhon", nó đã gợi ý ra "iPhone 15".
- Log Analytics & Monitoring (ELK Stack): Thu thập log từ hàng nghìn server, lưu vào ES và dùng Kibana để vẽ biểu đồ lỗi, traffic, tấn công DDoS theo thời gian thực.
- Enterprise Search: Tìm kiếm nội bộ trong doanh nghiệp (tìm văn bản, email, PDF, nhân sự...).
- SIEM (Security Information and Event Management): Phát hiện các hành vi bất thường trong bảo mật mạng.
5. Minh họa Query (Elasticsearch DSL)
Elasticsearch sử dụng RESTful API và ngôn ngữ truy vấn dạng JSON gọi là Domain Specific Language (DSL).
Kịch bản: Trang thương mại điện tử tìm kiếm Laptop.
Bước 1: Tạo Index và Mapping (Định nghĩa cấu trúc dữ liệu)
PUT /products
{
"mappings": {
"properties": {
"name": { "type": "text" }, // Dùng cho full-text search
"price": { "type": "integer" },
"brand": { "type": "keyword" } // Dùng cho lọc chính xác (exact match)
}
}
}Bước 2: Ghi dữ liệu (Indexing)
POST /products/_doc/1
{
"name": "MacBook Pro M1 2020",
"price": 1200,
"brand": "Apple"
}Bước 3: Tìm kiếm Full-text (Match Query)
Tìm tất cả sản phẩm có chữ "macbook" (không phân biệt hoa thường).
GET /products/_search
{
"query": {
"match": {
"name": "macbook"
}
}
}Bước 4: Truy vấn phức hợp (Bool Query)
Tìm "MacBook" NHƯNG giá phải dưới 2000 VÀ của hãng Apple. Đây là loại query mạnh mẽ nhất.
GET /products/_search
{
"query": {
"bool": {
"must": [
{ "match": { "name": "macbook" }} // Phải khớp từ khóa
],
"filter": [
{ "term": { "brand": "Apple" }}, // Lọc hãng Apple
{ "range": { "price": { "lte": 2000 }}} // Giá <= 2000
]
}
}
}Kết luận
Elasticsearch đại diện cho một bước chuyển mình quan trọng trong lĩnh vực Truy hồi Thông tin (Information Retrieval), nơi trọng tâm chuyển dịch từ việc "lưu trữ bền vững" sang khả năng "khám phá dữ liệu" (Data Discovery) với độ trễ thấp.
Trong kiến trúc phần mềm hiện đại, Elasticsearch hiếm khi đứng độc lập mà thường đóng vai trò là lớp bổ trợ (Auxiliary Layer) bên cạnh các hệ quản trị cơ sở dữ liệu quan hệ (RDBMS). Sự kết hợp này tạo ra mô hình Polyglot Persistence, tận dụng tính toàn vẹn dữ liệu của SQL và khả năng phân tích, tìm kiếm phi cấu trúc mạnh mẽ của Lucene Index. Đối với các kỹ sư hệ thống, việc làm chủ Elasticsearch không chỉ là học một công cụ mới, mà là nắm bắt tư duy xử lý dữ liệu quy mô lớn, nơi tốc độ truy xuất tri thức trở thành lợi thế cạnh tranh cốt lõi.

