Canva cần một hệ thống để đếm số lượt sử dụng, các lượt đếm này không chỉ là lượt sử dụng các mẫu thiết kế, mà còn bao gồm cả hình ảnh, video, và các loại nội dung khác. Thử tưởng tượng với số lượng người dùng của Canva thì việc đếm này lớn đến mức nào. Cùng tìm hiểu bài toán đằng sau nhé
Tags: #system design, #canva, #OLAP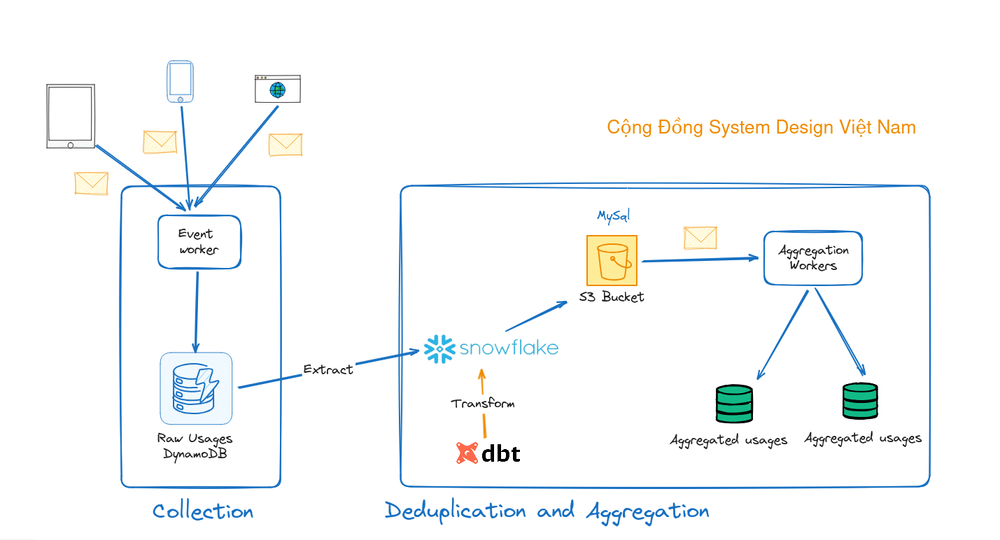
Từ ngày có canva, các anh em làm Slide mô tả mà cần màu mè 1 tí, muốn làm cái banner cho page của công ty hay đơn giản là cắt ghép ảnh để troll bạn bè cũng đã trở lên vô cùng nhanh chóng phải không nào 😂😂😂
Mà anh em dùng canva thì mua canva pro đi nhé đừng mua chui nhé để ủng hộ các anh em dev tại Canva nhé =)))Hôm nay chúng ta cùng tìm hiểu một bài toán lớn tại Canva, và một solution cực kỳ hiệu quả mà các kỹ sư vô cùng tài năng tại Canva đã triển khai
Đặt Vấn Đề
Các design mẫu trên canva bản thân mình thấy khá đẹp đẽ và có thể sử dụng luôn cho Design của anh em,
Vậy anh em có biết các mẫu design đó đến từ đâu không?
Đó là 1 phần lớn nhờ vào chương trình Canva Crreators, nó là một sáng kiến của Canva nhằm khuyến khích và hợp tác với các nhà sáng tạo nội dung để phát triển và cung cấp các tài nguyên thiết kế cho người dùng. Các nhà sáng tạo tham gia chương trình có cơ hội kiếm tiền từ nội dung mà họ đóng góp và được trả tiền dựa trên số lần mọi người sử dụng nội dung của họ
Từ đó họ cần một hệ thống để đếm số lượt sử dụng, các lượt đếm này không chỉ là lượt sử dụng các mẫu thiết kế, mà còn bao gồm cả hình ảnh, video, và các loại nội dung khác. Thử tưởng tượng với số lượng người dùng của Canva thì việc đếm này lớn đến mức nào 😄😄😄Với tốc độ tăng trưởng của mình thì cứ 18 tháng, số lượt sử dụng các Design sẵn này lại tăng gấp đôi, lượng xử lý của hệ thống đếm cần tăng gấp đôi. Và đến này họ cần xử lý cho hàng tỷ lượt sử dụng mỗi tháng
Thách Thức
Với các yêu cầu đó, hệ thống đếm số lượt sử dụng này cần gặp 3 thách thức lớn chính:Độ Chính Xác (Accuracy):
Khả Năng Mở Rộng (Scalability):
Khả Năng Vận Hành (Operability):
Bắt đầu hành trình thử nghiệm
Bắt đầu từ những thứ quen thuộc - MySql:
Với giải pháp đầu tiên được đưa ra, họ sử dụng MySql - một thứ mà cả team đã quá quen thuộc.
Kiến trúc gồm 3 thành phần chính tách biệt và sử dụng các workers để vận hành giữa các tầng.
3 thành phần chính của kiến trúc:
Khó khăn gặp phải
Quả trình loại bỏ trùng lặp trên kiến trúc trên là một quy trình tuần tự đơn luồng, sử dụng một con trỏ để lưu trữ bản ghi đã được quét gần nhất.
Thiết kế này giúp dễ dàng để theo dõi, đặc biệt khi có sự cố hoặc vấn đề cần kiểm tra việc sửa chữa dữ liệu bị hỏng vì nó rõ ràng cho biết những bản ghi nào đã được xử lý và những bản ghi nào chưa được xử lý.
Tuy nhiên, thiết kế này không thể mở rộng vì việc xử lý mỗi bản ghi sử dụng yêu cầu ít nhất một lần truy vấn cơ sở dữ liệu với một lần đọc bản ghi sự kiện và một lần ghi để tăng số đếm sử dụng, như được mô tả trong sơ đồ trên. Do đó, một quét hoàn chỉnh sẽ mất O(N) truy vấn cơ sở dữ liệu, trong đó N là số lượng bản ghi sử dụng.
Chắc hẳn anh em sẽ nghĩ tại sao không xử lý theo lô nhiều record 1 lúc. Nhưng việc xử lý theo cách đó không cải thiện cơ bản khả năng mở rộng vì độ phức tạp là O(N / C) vẫn là O(N) với kích thước lô không đổi C. Quét đa luồng có thể là một tối ưu hóa khác, nhưng nó sẽ làm tăng đáng kể độ phức tạp của mã và làm cho việc bảo trì và khắc phục sự cố trở nên khó khăn hơn.
Ngoài ra, lỗi xử lý cho bất kỳ record nào sẽ làm chậm tất cả các bản ghi tiếp theo, cũng như các giai đoạn xử lý sau đó.
Trở ngại với chính MySQL
Kiến trúc ban đầu này dựa trên MySQL ưu tiên sự đơn giản và quen thuộc hơn là khả năng mở rộng. MySQL không tận dụng được sức mạnh của hệ thống phân tán và xử lý song song. MySQL RDS không tự động mở rộng theo chiều ngang, dẫn đến việc phải tăng kích thước phiên bản định kỳ khoảng 8-10 tháng 1 lần, làm tăng chi phí hoạt động. Khi kích thước của RDS đạt vài TB, việc duy trì trở nên đắt đỏ và việc khắc phục sự cố gặp khó khăn vì phải sửa dữ liệu thủ công trong cơ sở dữ liệu.
Thử nghiệm với DynamoDB
Để khắc phục hạn chế của MySql, cả team đã chuyển sang dùng DynamoDB nhờ vào khả xử lý khối lượng công việc lớn và thông lượng cao - điều này phù hợp hoàn hảo với nhu cầu dữ liệu ngày càng tăng của Canva.
Họ dịch chuyển việc lưu trữ các dữ liệu đầu vào sang DynamoDB, đã đem lại cải thiện đáng kể. Và anh em tại Canva đã nghĩ đến việc dịch chuyển tất cả MySql trong kiến trúc sang DynamoDB - thứ khiến họ phải code lại nhiều phần nhưng hứa hẹn đem lại sự cải thiện vô cùng lớn cho hệ thống.
Nhưng họ nhận ra vấn đề thực sự lại không nằm ở Database, mà nút thắt thực sự của hệ thống là các vòng truy vấn Database liên tục - hệ thống phải thực hiện nhiều truy vấn đến cơ sở dữ liệu để xử lý từng bản ghi hoặc từng giai đoạn trong quá trình
Bài học rút ra: Hệ thống chậm thì đừng đổ lỗi cho database 😆😆😆
Giải pháp mới với OLAP
Canva đã tiến thành chuyển từ cơ sở dữ liệu OLTP truyền thống sang OLAP, và đặc biệt sử dụng Snowflake.
Kiến trúc mới đã thay đổi cách Canva xử lý và lưu trữ dữ liệu sử dụng, áp dụng phương pháp ELT (Trích xuất, Tải, Chuyển đổi).
Đầu tiên, các dữ liệu thông tin sử dụng các Design từ các trình duyệt web, mobile app như cũ và lưu vào DynamoDB. Sau đó dữ liệu này sẽ được tải vào Snowflake bằng 1 pipeline sao chép dữ liệu ổn định và chính xác (data replication pipeline) được cung cấp bởi đội hạ tầng tại chính CanvaGiai đoạn chuyển đổi sử dụng khả năng tính toán mạnh mẽ của Snowflake. Nó cũng sử dụng DBT (Công cụ xây dựng dữ liệu) để xác định các phép biến đổi phức tạp.
Những phép biến đổi này được viết dưới dạng các truy vấn giống SQL, cho phép tính toán từ đầu đến cuối trực tiếp trên dữ liệu nguồn.
Ví dụ: một phép chuyển đổi đã tổng hợp mức sử dụng của mỗi brand bằng cách sử dụng truy vấn SQL đã chọn dữ liệu từ bước trước đó có tên là 'daily_template_usages' và nhóm dữ liệu đó theo 'day_id' và 'template_brand'.
Các bước chính trong quá trình chuyển đổi như sau:
Kiến trúc mới này đã loại bỏ các đầu ra trung gian, thay vì lưu giữ dữ liệu ở các giai đoạn quy trình khác nhau, Canva đã cụ thể hóa các kết quả chuyển đổi trung gian dưới dạng SQL Views. Trước đây, mỗi giai đoạn của pipeline có thể lưu trữ dữ liệu tạm thời vào các bảng hoặc tập tin trung gian. Điều này có thể tạo ra nhiều dữ liệu tạm thời, gây tốn kém và phức tạp trong việc quản lý. Thay vì vậy Canva sử dụng SQL Views để hiện thực hóa các đầu ra của phép biến đổi trung gian.
SQL Views là các truy vấn lưu trữ dưới dạng ảo trong cơ sở dữ liệu, cho phép bạn truy xuất dữ liệu đã biến đổi mà không cần lưu trữ nó vào các bảng thực tế.
Lợi ích từ OLAP
Cải thiện tốc độ và khả năng scale
OLAP đã giúp Canva tách biệt được việc lưu trữ và tính toán, cho phép họ có thể scale phần tính toán một cách độc lập. Canva đã có thể thực hiện tổng hợp hoàn toàn hàng tỷ bản ghi sử dụng trong vài phút vì hầu hết các phép tính hiện được thực hiện trong bộ nhớ, nhanh hơn nhiều so với các vòng truy vấn cơ sở dữ liệu. Chúng tôi cũng đã giảm độ trễ của toàn bộ pipeline từ hơn một ngày xuống dưới 1 giờ.
Giảm độ phức tạp trong tính toán và codebase
Việc xử lý sự cố trở nên dễ quản lý hơn. Hầu hết các vấn đề có thể được giải quyết bằng cách chạy lại quy trình từ đầu đến cuối mà không cần can thiệp cơ sở dữ liệu thủ công. Ngoài ra Canva đã giảm hơn 50% dữ liệu được lưu trữ và loại bỏ hàng nghìn dòng code tính toán tổng hợp và chống trùng lặp cũ. Logic viết lại bằng SQL đơn giản hơn so với code trước đó. Nhờ giảm độ phức tạp mà số lượng sự cố giảm đáng kể xuống còn khoảng vài tháng 1 lần
Những thách thức từ giải pháp mới
Mặc dù giải pháp mới mang lại nhiều lợi ích, nó cũng đặt ra những thách thức quan trọng:
Bài học rút ra từ Canva
Và đó là tổng quan hệ thống của Canva giúp tính toán lượt sử dụng các mẫu thiết kế sẵn 1 cách chính xác và có chịu tải cao. Qua bài này anh em có thể rút ra vài kinh nghiệm như: Bài viết đã nêu rõ các thách thức trong việc đếm dữ liệu cho thanh toán cho người sáng tạo và hành trình phát triển kiến trúc của Canva, từ giải pháp ban đầu với MySQL đến việc thử nghiệm với DynamoDB và Snowflake. Các bài học quan trọng bao gồm:
Nếu thấy bài viết hay thì hãy cho chúng mình xin 1 share để team có động lực đem đến những bài viết chất lượng hơn nha
Tham khảo thêm
Chia sẻ từ chính Canva: https://www.canva.dev/blog/engineering/scaling-to-count-billions/